Google Summer of Code Progress August 7
Yay! We have dynamically generated gallery and tutorials page now!
Progress so far
The major changes are in the gallery and in the new tutorials page.
Gallery Page
Instead of showing the manually entered images from the admin panel, the gallery now fetches all images from all the tutorials in the latest documentation.
This is actually done using by scraping the tutorials page from the json docs.
Although the docs are now built in json format but still the body is represented as an HTML string. As a result there was no way out other than parsing the HTML. And the best HTML parsing library that I know of is Beautiful Soup.
def get_doc_examples_images():
"""
Fetch all images in all examples in latest documentation
"""
doc = DocumentationLink.objects.filter(displayed=True)[0]
version = doc.version
path = 'examples_index'
repo_info = (settings.DOCUMENTATION_REPO_OWNER,
settings.DOCUMENTATION_REPO_NAME)
base_url = "http://%s.github.io/%s/" % repo_info
url = base_url + version + "/" + path + ".fjson"
response = requests.get(url)
if response.status_code == 404:
url = base_url + version + "/" + path + "/index.fjson"
response = requests.get(url)
if response.status_code == 404:
return []
url_dir = url
if url_dir[-1] != "/":
url_dir += "/"
# parse the content to json
response_json = response.json()
bs_doc = BeautifulSoup(response_json['body'], 'html.parser')
all_links = bs_doc.find_all('a')
examples_list = []
for link in all_links:
if(link.get('href').startswith('../examples_built')):
rel_url = "/".join(link.get('href')[3:].split("/")[:-1])
example_url = base_url + version + "/" + rel_url + ".fjson"
example_response = requests.get(example_url)
example_json = example_response.json()
example_title = strip_tags(example_json['title'])
# replace relative image links with absolute links
example_json['body'] = example_json['body'].replace(
"src=\"../", "src=\"" + url_dir)
# extract title and all images
example_bs_doc = BeautifulSoup(example_json['body'], 'html.parser')
example_dict = {}
example_dict['title'] = example_title
example_dict['link'] = '/documentation/' + version + "/" + path + "/" + link.get('href')
example_dict['description'] = example_bs_doc.p.text
example_dict['images'] = []
for tag in list(example_bs_doc.find_all('img')):
example_dict['images'].append(str(tag))
examples_list.append(example_dict)
return examples_listAnd all the extracted images are displayed in the honeycomb gallery.

Tutorials Page
Although each version of documentation has a list of tutorials separately, we wanted a dedicated page which will contain the tutorials with thumbnails and descriptions and they will be grouped into several sections. So similar to the gallery page I parsed the tutorials index page and went into each tutorial and fetched the thumbnails and descriptions. Then this list of tutorials is displayed as an exapandable list of groups.
def get_examples_list_from_li_tags(base_url, version, path, li_tags):
"""
Fetch example title, description and images from a list of li tags
containing links to the examples
"""
examples_list = []
url_dir = base_url + version + "/" + path + ".fjson/"
for li in li_tags:
link = li.find("a")
if(link.get('href').startswith('../examples_built')):
example_dict = {}
# get images
rel_url = "/".join(link.get('href')[3:].split("/")[:-1])
example_url = base_url + version + "/" + rel_url + ".fjson"
example_response = requests.get(example_url)
example_json = example_response.json()
example_title = strip_tags(example_json['title'])
# replace relative image links with absolute links
example_json['body'] = example_json['body'].replace(
"src=\"../", "src=\"" + url_dir)
# extract title and all images
example_bs_doc = BeautifulSoup(example_json['body'], 'html.parser')
example_dict = {}
example_dict['title'] = example_title
example_dict['link'] = '/documentation/' + version + "/" + path + "/" + link.get('href')
example_dict['description'] = example_bs_doc.p.text
example_dict['images'] = []
for tag in list(example_bs_doc.find_all('img')):
example_dict['images'].append(str(tag))
examples_list.append(example_dict)
return examples_list
def get_doc_examples():
"""
Fetch all examples (tutorials) in latest documentation
"""
doc_examples = []
doc = DocumentationLink.objects.filter(displayed=True)[0]
version = doc.version
path = 'examples_index'
repo_info = (settings.DOCUMENTATION_REPO_OWNER,
settings.DOCUMENTATION_REPO_NAME)
base_url = "http://%s.github.io/%s/" % repo_info
url = base_url + version + "/" + path + ".fjson"
response = requests.get(url)
if response.status_code == 404:
url = base_url + version + "/" + path + "/index.fjson"
response = requests.get(url)
if response.status_code == 404:
return []
url_dir = url
if url_dir[-1] != "/":
url_dir += "/"
# parse the content to json
response_json = response.json()
bs_doc = BeautifulSoup(response_json['body'], 'html.parser')
examples_div = bs_doc.find("div", id="examples")
all_major_sections = examples_div.find_all("div",
class_="section",
recursive=False)
for major_section in all_major_sections:
major_section_dict = {}
major_section_title = major_section.find("h2")
major_section_dict["title"] = str(major_section_title)
major_section_dict["minor_sections"] = []
major_section_dict["examples_list"] = []
all_minor_sections = major_section.find_all("div",
class_="section",
recursive=False)
if len(all_minor_sections) == 0:
# no minor sections, only examples_list
all_li = major_section.find("ul").find_all("li")
major_section_dict[
"examples_list"] = get_examples_list_from_li_tags(base_url,
version,
path,
all_li)
else:
for minor_section in all_minor_sections:
minor_section_dict = {}
minor_section_title = minor_section.find("h3")
minor_section_dict["title"] = str(minor_section_title)
minor_section_dict["examples_list"] = []
all_li = minor_section.find("ul").find_all("li")
minor_section_dict[
"examples_list"] = get_examples_list_from_li_tags(base_url,
version,
path,
all_li)
major_section_dict["minor_sections"].append(minor_section_dict)
doc_examples.append(major_section_dict)
return doc_examples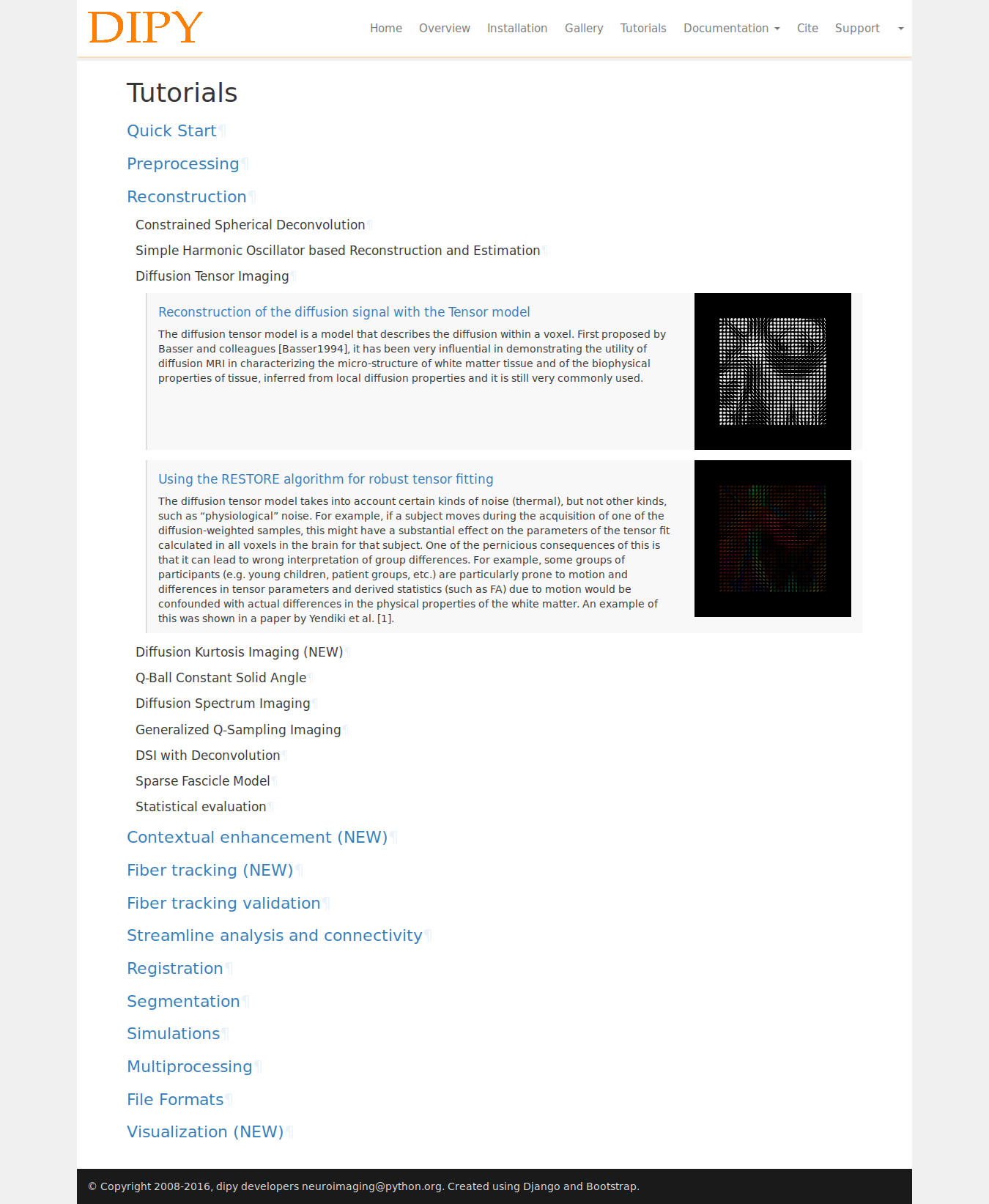
What next?
The github statistics visualizations page is one major task. Another major task is somehow make the automatically generated gallery and tutorials page editable so that we can change the thumbnails or descriptions. Also the coding period is about to end in 2 weeks so documenting the code and merging all pull requests is a priority.
Posted with Tags: